
[Statistical Study]MIT Notebook-chapter 9.3
Updated:
MIT Notebook-chapter 9.3
First Part Inference for one way count data Chi-Square test using the multinoial distribution
- 단측 count data의 추정을 위해 다항(multinomial) 분포를 이용한 카이제곱 검증
다항분포는 범주형 자료의 확률모형을 나타내는 예로서 이 모형을 이용하여 카이제곱검정의 통계량을 만들 수 있다
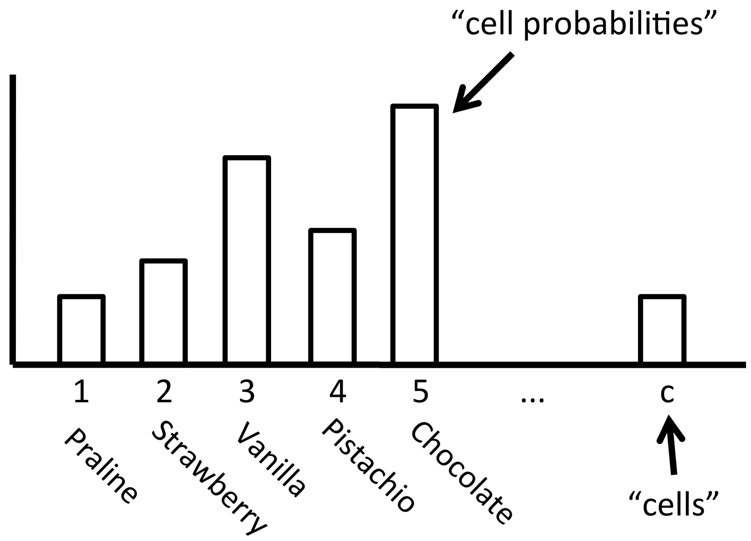
다항(Multinomial) 분포의 예시 - 아이스크림 맛의 선호도
해당 검증을 위해 아래와 같은 조건이 있다
- Cell은 1, 2, …, c로 넘버링이 되어 있다
-
셀의 확률은 아래와 같다 \(p_1, p_2, ..., p_c, Where \sum_{i}p_i=n\)
-
셀의 개수는 아래와 같다 \(n_1, n_2, ..., n_c, Where \sum_{i}n_i = n\)
- 다항 분포의 확률 \(P(N_1 = n_1, N_2 = n_2, ...) = \frac{n!}{n_1!n_2!...n_c!}p_1^{n_1}p_2^{n_2}...p^{n_c}\)
우리는 아래와 같은 검증을 진행하려 한다. 과거와 현재의 마켓쉐어가 같을까?
\(H_0 : p_1 = p_{10}, p_2 = p_{20}, ..., p_c = p_{c0}\) \(H_1: p_i \neq p_{i0}\)
우선 검증 평균 \(X^2\)를 설정하자. → 멘델의 적중률 검정을 따른다.
여기서 $e_i$는 $X_i$의 평균이라고 볼 수 있다.
\[e_i = np_{i0} \leftarrow expected \;cell\;counts\;when\; H_0\; is\; true\] \[X^2 = \sum_{i=1}^{c}\frac{(n_i-e_i)^2}{e_i} = \sum_{i}\frac{(observed_i-expected_i)^2}{expected_i}\]- $X^2$를 관찰된 개수가 기대count와 얼마나 다른지 차이라고 생각해야 한다.
- $X^2$가 크다는 것은 → 관찰된 것이 기대보다 많이 다르다는 것을 의미한다, 이말은, 뭔가 잘못되었고 귀무가설이 채택되기 때문에 안된다.
카이제곱 분포(Chi-square distribution)란?
확률변수 Z1,Z2,⋯,Zn이 독립이고 표준정규분포를 따른다고 하자. 확률변수
\[Y=Z_1^2 + Z_2^2 + ... + Z_n^2\]를 자유도 n인 카이제곱분포라고 한다.
다시 돌아가, 위에 수식을 보자.
\[X^2 = \sum_{i=1}^{c}\frac{(n_i-e_i)^2}{e_i} = \sum_{i}\frac{(observed_i-expected_i)^2}{expected_i}\]n이 커진다면, 위에서 설명한 카이제곱 분포에 근접헤 가는 것을 알 수 있다. 결국, 우리가 구한 $X^2$가 자유도 $c-1$인 원래 카이제곱 분포값보다 클 경우, 우리는 귀무가설을 기각할 수 있다.
- 중요한 포인트 : \(e_i >= 1이거나 e의 4/5이상이 >=5이어야 카이제곱 분포를 모사할 수 있음\)
Leave a comment